9 Tips for a Painless Microservices Migration
The InVision platform started on a monolithic codebase. Like many SaaS companies that have grown rapidly, we found ourselves needing to move to microservices in order to scale our pace of development across multiple engineering teams.
We’re not going to argue that we should have started with microservices first. In fact, we agree with Fowler’s MonolithFirst approach. The complexities of microservices will slow down a small team.
As we’re in the middle of moving to microservices, we found ourselves asking:
Knowing what we know now about microservices, what would we have done differently when we started building out InVision as a monolith?
In other words, what lessons can we apply to the next startup in which we build a monolith? When we do this again, how could we ensure it’s a smoother and (mostly) pain-free transition to microservices?
While still being cautious not to slow down early-stage development for the sake of an unpredictable future. Time is money, and every startup is limited by their runway. So, where do we draw the line between sensible, frugal future-proofing and costly premature optimization?
It’s tempting to say “we’d do nothing differently”. Hindsight is 20/20, after all. Even some of our own would argue to avoid the trap of microservices:
When you are starting out, you want to optimize for speed of development, and I’m not sure doing any sort of thinking about microservices is the right choice. - Ben Darfler, Lead Engineer
But I’m of the camp that there is always something to be learned from our past – so that our experience and choices may serve as a lesson for our future selves or others.
Here are some lessons we learned to make your next monolith to microservices migration faster and less painful.
1. Draw Domain Lines
Even if you’re not going to carve up your APIs and data storage into separate services, take the simple step of defining and documenting your business entities early on. These can and should be very coarse-grained at first.
Your monolith should not be a meme.
When you’re coding, be mindful of how you cross the boundaries of these entities.
Try not to circumvent the class boundaries when coding complex tasks. Respect them! Dependency injection may make it convenient to reference and use any other library or service class within your monolith, but this practice can quickly get you into an architectural rats nest.
Try not to do SQL JOINs or DB transactions across boundaries. Not only will this not scale when you want to break out to microservices, it will slow down your query performance as the number of rows increase, too.
I would have moved more SQL
JOINstatements out of the database and into the application server. I love SQL, and the younger me would often try to find ways to make the database do as much work as possible, joining this table to that table, running aggregations, and coalescing various columns. However, as we began to scale, it quickly became apparent that the database does not scale as well as the application servers. And, by moving theJOINs into the code, we could have made our queries faster, easier to reason about, and less CPU intensive. - Ben Nadel, Founding Engineer
Other than future microservice implications, this will also eventually cause database lock timeouts and degrade your DB performance.
When you keep your SQL JOINs simple, it will be much less painful to break those JOINs out into cross-service calls later on.
2. Document Your URL Route Domains
By the time we started carving out microservices, we had over 700 URL routes defined in the monolith’s route handler. How did we know which URL routes belonged in our brand new domain-specific microservice? We didn’t.
As developers, we like to think that all our URL route structures will be entirely logical. You know, every
users-related URL path will start with /users and they’ll all be grouped together in the routes file. When you have
a team of 5, of course all the engineers will follow that standard (you hope). When you grow to a team of 50 and have
100s of routes, assume that a new engineer will just add a new route somewhere else using a different convention.
Adopt a standard in the routes files for documenting the domain to which that URL route belongs.
// Domain: Comments
{ "$POST/api/comments" = "/api:comments/create" },
// Domain: Screen Groups (START)
{ "$POST/api/screen-group/create" = "/api:screen_groups/create" },
{ "$POST/api/screen-group/update" = "/api:screen_groups/update" },
{ "$POST/api/screen-group/update-sort" = "/api:screen_groups/updateSort" },
{ "$POST/api/screen-group/delete" = "/api:screen_groups/delete" },
// Domain: Screen Groups (END)
3. Be Explicit About Routes And Methods
Do not use wildcard routes, like these:
// API: generic RESTful requests
{ "$DELETE/api/:resource/:id" = "/api::resource/delete/id/:id" },
{ "$GET/api/:resource/:id" = "/api::resource/get/id/:id" },
{ "$POST/api/:resource/:id" = "/api::resource/update/id/:id" },
{ "$POST/api/:resource" = "/api::resource/create" },
The above routes could be used to handle multiple domain entities, but how would you know which ones? When you’re about to move the handling of an entire domain entity out to a microservice, you’ll need to know. So be explicit!
Furthermore, don’t use wildcard verbs/HTTP methods (is this a GET or a POST, or both?):
{ "/api/layersync/items" = "/api:layerSync/items" },
This pattern will give you no REST when moving to a microservice.
Hopefully you’ve instrumented your URL endpoints, so you know how it’s being hit, but if you haven’t, it’s going to be very difficult to determine how this endpoint is being used. And therefore, it’s going to be difficult to work out how to migrate it effectively to a microservice.
This is also useful when sunsetting features, as noted by LinkedIn’s Lessons Learned from Decommissioning a Legacy Service:
When removing one endpoint, I thought it was a simple endpoint that could be migrated by redirecting it to an alternative endpoint. But after doing this, another team complained that some functionality was broken. I figured out that part of the endpoint that served very limited traffic used HTTP POST, while 99% of traffic used HTTP GET.
4. Assign URL Endpoint Ownership
Carrying over from the last tip, you should also be explicit about ownership. Ownership isn’t about who is allowed to touch the code, but rather about who is responsible for its operation in production. Drawing domain lines will only aid in determining this ownership, and likely result in a clean formation of teams in the future.
We didn’t identify owners early, but if we had, we would have used our routes file to document the team that owns each endpoint in the monolith:
// Domain: Comments, Team: Red Team
{ "$POST/api/comments" = "/api:comments/create" },
// Domain: Screen Groups (START), Team: Gold Team
{ "$POST/api/screen-group/create" = "/api:screen_groups/create" },
{ "$POST/api/screen-group/update" = "/api:screen_groups/update" },
{ "$POST/api/screen-group/update-sort" = "/api:screen_groups/updateSort" },
{ "$POST/api/screen-group/delete" = "/api:screen_groups/delete" },
// Domain: Screen Groups (END)
When you’re a small group of engineers, it can be awkward to assign ownership at the engineer level because everyone feels its a shared responsibility. Our advice is to be explicit, even if multiple owners are identified. Don’t let any URL endpoint have ambiguous ownership. Not only should you be using ownership documentation to determine which who is responsible for the operation and monitoring of that endpoint, but when it comes time to carve it out into a microservice, you know exactly who to talk to about it.
5. Monitor URL Usage
Did we mention you should be instrumenting all those endpoints? While you should also be graphing the error rate and performance of every HTTP endpoint you expose, at the very least you should graph the request rate.
We weren’t. When it came time to break endpoints off the monolith, one of the first steps was to identify which endpoints were still receiving traffic and how much.
We identified approximately 25% of our endpoints were no longer used.
Dead URLs are a waste of screen real estate for your dashboards.
Some endpoints weren’t dead but were rarely hit. In the effort to break a section of the monolith out to a microservice, you might also consider removing a rarely used feature from the product entirely.
6. Kill Dead Code
When you’re growing rapidly, your codebase is going to grow rapidly too. Be extra diligent about cleaning up dead code. Delete it. Don’t just comment it out – don’t leave it there at all.
// I am not sure if we need this, but too scared to delete.
You have source code control for history, if you need it. But unless you’re rolling back a deployment, you will rarely, if ever, need to go back and reference that code.
7. Build (and Document) Ports & Adapters
When you’re building your monolith, use an hexagonal architecture – build abstraction ports for all incoming requests and build abstraction adapters for all outgoing requests.
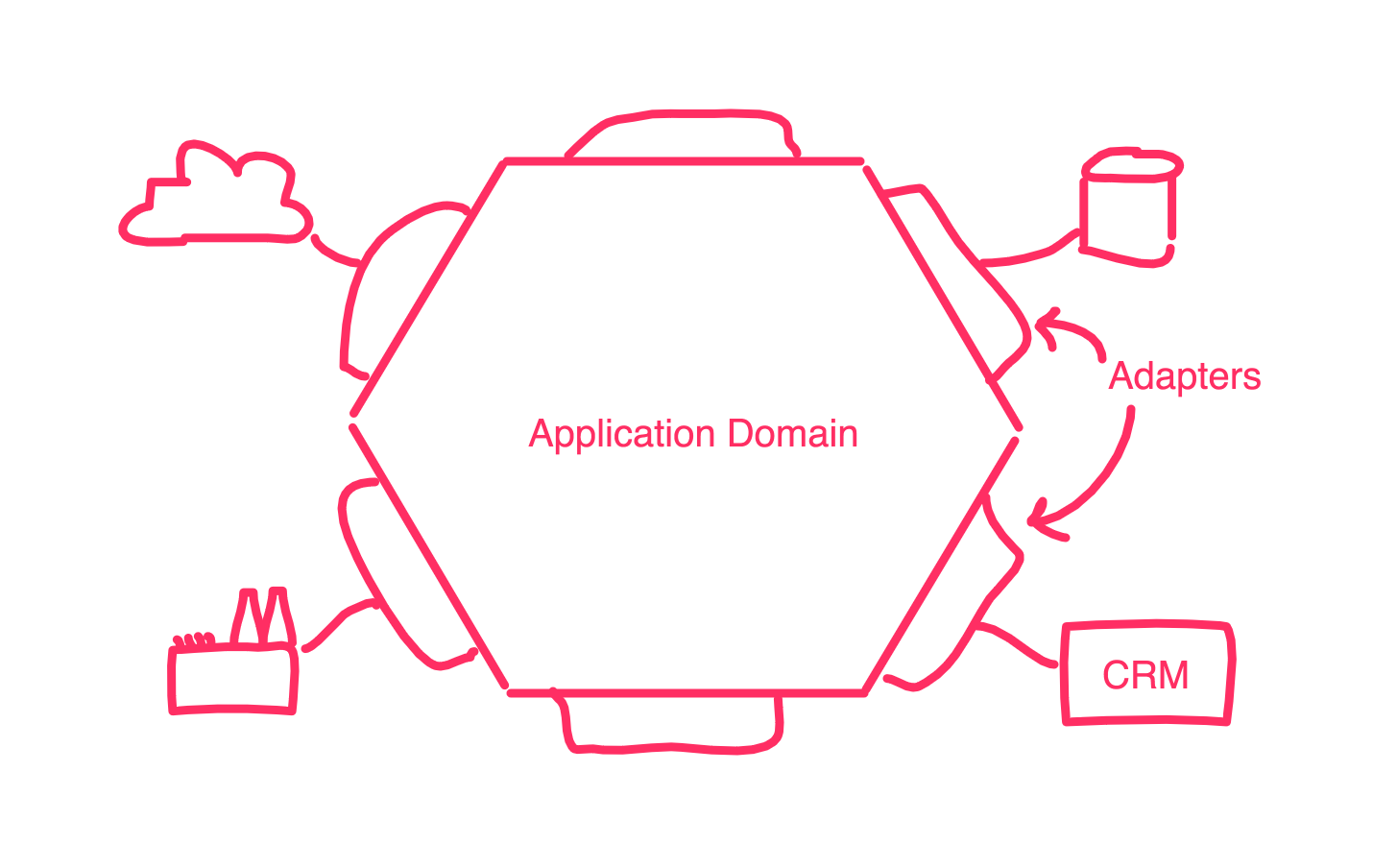
Possibly common sense to most, but when you’re moving quickly and adding new team members, they don’t have all the context for what ports and adapters already exist. So it’s likely they end up building a direct connection to another API or building another adapter class for it. And this can lead to a big mess when you’re trying to carve out edges of your monolith into microservices.
For example, our monolith had a handful of places in the code that would read or write Amazon S3 objects. Some of those places used a standard service class and some of those places used the S3 API directly. When it came time to swap out our S3 implementation details (by moving them to a microservice), we had to find and swap out all the places using S3 directly instead of just swapping out the adapter class.
8. Build a Shared Service Catalog
When you’re building services, ports, or adapters, document them somewhere all your new contributors will reference. We refer to this as our Service Catalog. This will decrease the likelihood new contributors re-invent the same systems, and thus decrease the complexity of carving that area of the code out into a microservice later.
9. Document Your Environment Variables
Breaking out into microservices means you’re also breaking out the deployment configuration. Our monolith had over 200 environment variables. 😱
Without documentation, it was extremely difficult to know what they were for, if they were still necessary at all, and more importantly, which were relevant to the area of code that was being moved to a microservice.
So, please, document what environment variables a service, class, module uses. You’ll thank yourself later.
Conclusion
Many of the above tips may seem like common sense, and most of them can be summarized as “create clean boundaries” and “write things down”, but when you’re moving fast, it’s easy to forget these disciplines.
And that’s really the most important tip: when you get started, set out some standards and be disciplined in meeting them. But be cautious your standards don’t add unnecessary overhead. We’ve tried to be diligent in outlining tips we believe balance that overhead with future value.
Finally, the next time you’re wading through the monolithic codebase and feeling crushed by the weight of it, take a moment to remember where that codebase got you.